
Adversarial Attacks on Machine Learning Models: What Software Developers Need to Know
Machine learning and artificial intelligence have emerged as powerful tools in several domains, bringing huge changes to software development. LLMs are now used by developers to help write code and are integrated into apps and services. Similarly, other machine learning models are commonly integrated into websites and apps, either being developed and trained from scratch using proprietary data, or leveraging third party machine learning tools. In both cases, similarly to how LLMs are susceptible to prompt injection attacks, machine learning models can be targeted by adversarial attacks, and it is of crucial importance that software developers are aware of the threat landscape, the risks, and the possible mitigation measures that can be put in place to prevent and combat these attacks. In this post, we will provide an introduction to adversarial attacks, discuss the threat landscape and mitigation techniques that developers should be aware of.
The threat landscape
Adversarial machine learning refers to the study of techniques that are designed to manipulate machine learning models by exploiting their inherent weaknesses.They pose a significant threat to the reliability, integrity, and security of machine learning systems, as they might cause them to behave in unexpected ways or leak information about the models (e.g., training data). Below are some attacks that it is important to be aware of.
Perturbation Attacks
Perturbation attacks manipulate input data to mislead a machine learning model. By adding carefully crafted perturbations – for instance adding imperceptible noise to images or modifying textual input, an attacker can make subtle changes that lead to misclassification or wrong predictions. An important aspect to consider is that, most of the times, these perturbations are such that they are not immediately visible to humans, but can still lead the model to produce completely wrong outputs, as in the example below from an OpenAI blog post:
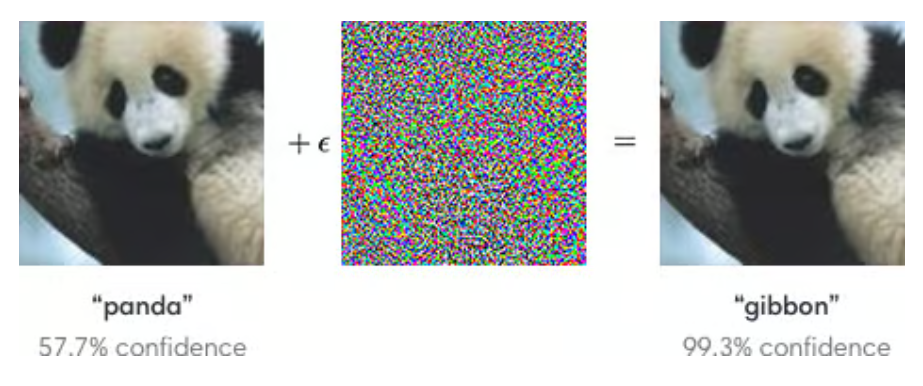
A given image classification model is capable of correctly labeling as “panda” the image on the left (with 57% confidence) but, when the image is modified by adding the carefully crafted noise shown in the middle, the model wrongly classifies the updated image as “gibbon” (and with a much higher confidence!), even though the differences are not visible to the human eye.
Poisoning Attacks
Poisoning attacks involve injecting malicious data into the training dataset used to train machine learning models. By intentionally polluting the training data, attackers can manipulate the model's behavior, leading to biased or incorrect predictions. These attacks are particularly effective when the model is trained using user-generated or crowdsourced data. Also, a crucial thing to consider about this is that most datasets are (generally unwillingly) victims of poisoning attack, as they contain several biases which are then exhibited by the trained models. Example of such biases are:
- Sampling Bias: when the dataset is not representative of the entire population (e.g., facial recognition model is predominantly trained on lighter-skinned individuals, it may perform poorly on darker-skinned individuals);
- Selection Bias: when training data is collected or labeled in a biased manner, it can lead to selection bias (e.g., if a loan approval model is trained on historical data that unfairly favored certain demographics, it may perpetuate discriminatory lending practices).
- Stereotyping Bias: machine learning models may learn stereotypes present in the training data and perpetuate them in their predictions (e.g., a model trained on job application data that exhibits gender biases may inadvertently associate certain professions with specific genders, leading to biased hiring decisions).
- Temporal Bias: if the training data does not adequately represent the changes or trends over time, the model may be biased towards past patterns and fail to adapt to new circumstances.
Model Extraction Attacks
In model extraction attacks, adversaries aim to obtain a replica or an approximation of a trained machine learning model (similarly to how reverse engineering aims at reproducing the code of a given software piece). By querying the model and analyzing its responses, attackers gradually reconstruct a functioning copy, which can then be exploited for various purposes, such as intellectual property theft or launching further attacks. Here you can find an interesting example.
Mitigation Techniques
To mitigate the risks associated with adversarial attacks, software developers can adopt several proactive measures. We list below some essential techniques to consider, but please bear in mind that not all of them can be used both for models that are trained from scratch and third party models or machine learning services, as it depends on how much insights into the models you have.
Adversarial Training
Developers should aim at building models with robust architectures that are resistant to adversarial attacks. An approach to do this is adversarial training, which consists of injecting adversarial samples (as the modified image of the panda above) with the correct label in the training dataset. With this approach, the model becomes more robust towards other adversarial samples as well. However, it is always an arms race and it is not possible with this approach only to have a model that is perfectly robust towards adversarial attacks.
Regular Model Updating
This is true both for models which are built from the ground up and third party models. Similarly to any other piece of software, machine learning models should be kept up to date with the latest patches and security measures. Regular updates help address newly discovered vulnerabilities and ensure that models can defend against new types of attacks.
Input Sanitization and Validation
Implementing strict input sanitization and validation procedures can help detect and mitigate potential adversarial attacks. Carefully inspecting and verifying input data for unexpected patterns or anomalies can prevent malicious inputs from influencing the model's behavior. This, for instance, could be done by leveraging an anomaly detection machine learning model, to study whether the input data provides some anomalous patterns and features. The objective, with this approach, is to guarantee that the input data belongs to the same “population” as the training data, which is an assumption of any machine learning model.
Ensemble and Redundancy
Using ensemble models, which combine predictions from multiple models, can enhance the robustness against adversarial attacks. Additionally, redundancy in models and data can make it harder for attackers to exploit specific weaknesses. On the flip side, this makes the training and running of the model more expensive and more time consuming, as several models need to be used in parallel.
Ongoing Monitoring and Evaluation
Lastly, in real-world scenarios it is crucial to continuously monitor and evaluate the machine learning models that you are using, to detect any possible anomalies in their behavior or events such as data drift that commonly occur in the wild. Implementing mechanisms to detect anomalies, unexpected outputs, or sudden drops in performance can help identify and mitigate potential adversarial attacks in a timely manner.
Conclusion
Adversarial attacks pose a significant threat to the integrity and reliability of machine learning models. Software developers must be aware of the threat landscape and adopt proactive measures to defend against such attacks. By understanding the types of attacks and implementing appropriate mitigation techniques, developers can strengthen the security and trustworthiness of their machine learning applications, ensuring their effectiveness and reliability in real-world scenarios. You should always try to stay vigilant, update your models regularly, and constantly monitor them.
We hope you found this read helpful and informative, and let us know in the comment what you think about it!




Ephedrine for sale, Pseudoephedrine for sale
Visit https://ephedrinepowders.com/ for Quality Ephedrine for sale, Pseudoephedrine for sale, Buy Ephedrine near me, Ephedrine for sale Online, Pseudoephedrine for sale Online,
Ephedrine HCl powder supplier from Australia. Wholesale Ephedrine powder vendor and Pseudoephedrine HCl powder supplier Australia.
!!!Ephedrine HCl powder shipping from Australia (Domestic)!!!
!!!Pseudoephedrine HCl powder shipping from Australia (Domestic)!!!
====! Bitcoin Accepted !====
Ephedrine Hydrochloride is produced by chemical synthesis and is marketed in the form of HCl salt.
Product Name: Ephedrine Hydrochloride
CAS Number: 134-71-4
Formula: C10H15NO · HCl
Formula Weight: 201.69 g/mol
Appearance (Color): White
Appearance (Form): Conforms to Requirements (Powder, Crystals, Granules, Crystalline Powder and/or Chunks)
Solubility (Turbidity): Clear 50mg/ml, H2O
Solubility (Color): Colorless
Purity (TLC) > 99 % _
Titration by AgNO3 98.5 – 101.5 %
Ephedrine is a decongestant and bronchodilator. It works by reducing swelling and constricting blood vessels in the nasal passages and widening the lung airways, allowing you to breathe more easily.
====! Bitcoin Accepted !====
DISCRETE PACKAGING
The item(s) will be vacuum packed, wiped using rubbing alcohol and packaged within at least 1 MBB bag. Every aspect of handling the contents of the package from packing to shipping is performed to withstand forensic.
RAPID ORDER PROCESSING
From the time you place your order to when it is shipped usually occurs within 24-48 hours, generally but could take longer depending on product availability.
DELIVERY GUARANTEE
We have a 100% delivery rate so far no packages have been seized, or lost!
Please contact for prices and availability – Wholesale & Retail Volumes
Ephedrine, Ephedrine HCL, Ephedrine powder, Pseudoephedrine, Pseudoephedrine HCl, Pseudoephedrine powder
Telegram: @alexmooris
Website: https://ephedrinepowders.com/